《AI×SCIENCE十大前沿观察》9:合成数据和数据基础设施
原创 集智与上智院 集智俱乐部
导语
上海科学智能研究院、集智科学研究中心和阿里云联合发布了《AI × Science十大前沿观察》,梳理出35个研究前沿,来推动科学发展的黄金时代到来。本篇为前沿观察9,扫描下方二维码,可获得完整版下载、快速链接论文原文。
扫描二维码 下载完整报告
合成数据和数据基础设施
背景介绍
在AI大模型时代,数据作为关键战略资源,既是模型训练的基础要素,也是制约性能提升的核心瓶颈,其质量与规模直接决定智能系统的能力边界。科学智能的发展同样面临着诸多数据挑战,其中最为关键的是数据稀缺问题[1]。一方面,在某些科学领域,往往难以获取大规模、高质量的标注数据[2];另一方面,某些数据资源丰富的领域(如医疗)往往涉及隐私或法律限制[3]。此外,跨学科多源数据整合也面临巨大障碍,数据格式、标准和结构的差异,导致AI模型难以跨越多个领域进行通用学习,进一步加剧了数据稀缺问题。
合成数据(Synthetic Data)与数据基础设施建设是解决以上挑战的两个重要手段。在合成数据中,最基础也最关键的是数据生成(Data Generation)问题。与传统提示工程不同[13][14],即通过提示对部署的LLMs输入文本数据 X 进行预测以生成标签 Y,合成数据生成则要求LLMs根据条件化的标签 Y 提示生成文本数据 X,以此适配多样化的下游任务的数据需求。
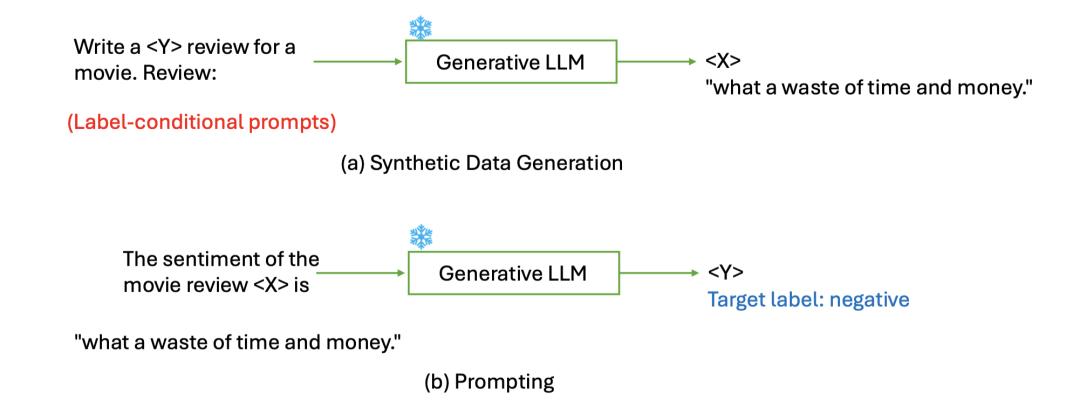
LLMs在生成特定标签的合成数据(a)与提示词预测生成标签(b)之间的比较 [13]|图片来源:Xu Guo&Yiqiang Chen.(2024) "Generative AI for Synthetic Data Generation: Methods,Challenges and the Future"
然而,若直接将有限标签和任务信息嵌入到提示中,LLMs生成的数据可能与任务无关,缺乏多样性,规模也很有限。因此需要更先进的提示技术:如属性控制提示(Attribute-controlled prompt),通过指定一组属性、并在提示模板中进行属性混合,以此定义任务获取合成数据的混合软提示方法 [15],或从LLMs中直接提取特定属性的提示,并查询生成特定数据的AttrPrompt [16];如词汇化技术(Verbalizer),通过将作为条件的属性类扩展为一组语义相似的提示来促进多样化数据生成,例如 MetaPrompt [17]首先从LLMs获取扩展提示,然后利用丰富的提示进一步提示LLMs生成数据。
LLMs生成特定属性任务训练数据的方法。同上[13]。
当然,以上合成数据生成方法,主要直接针对于文本数据等结构化的、序列化的数据,对于要保持全局一致性的复杂数据(如合成医学影像和3D图形),这些技术需要进行迁移和扩展。
除了数据生成,合成数据另外两个重要子领域是科学数据表示(Scientific Data Representation)和模型自我改进方向(Model Self-Improvement)的探索。前者重点研究如何有效地编码和组织合成数据,后者探索如何让模型通过合成数据来提升自身性能。高效的数据表征方法通过提取关键特征提升生成数据的保真度,而模型的自迭代优化机制则能持续扩展数据覆盖范围,二者的协同作用实现了高质量与规模化数据生成的同步突破。
下文中将重点介绍关于合成数据的数据生成、科学数据表示、模型自我改进三个领域的最新进展和代表性工作,以及科学数据基础设施建设的π-HuB项目。
研究进展
进展目录
合成数据生成:从序列数据到复杂数据
科学数据表示:从图神经网络到多模态数据表征
模型自我改进:通过合成数据提升AI系统性能
数据基础设施:人体蛋白质组计划
合成数据生成:从序列数据到复杂数据
推荐理由:合成数据的核心优势不仅在于可大规模生成数据,而且可以根据特定需求进行定制。通过引入可控的变化确保不同类别数据的平衡表示,增强模型的鲁棒性。在这个领域中,从简单的序列数据到复杂的多模态数据,都出现了一些突破性的研究成果。
在众多创新工作中,英伟达于2023年开发的 MimicGen系统展现出了特别的价值[4]。这个系统展示了如何从有限的人类示范中构建大规模训练数据集的有效方法。通过仅使用约200个人类演示样本,MimicGen成功生成了包含超过5万个示范的大规模数据集。这些数据涵盖了18种不同任务,并在多种场景配置、对象实例和机器人手臂操作中展现出良好的多样性。
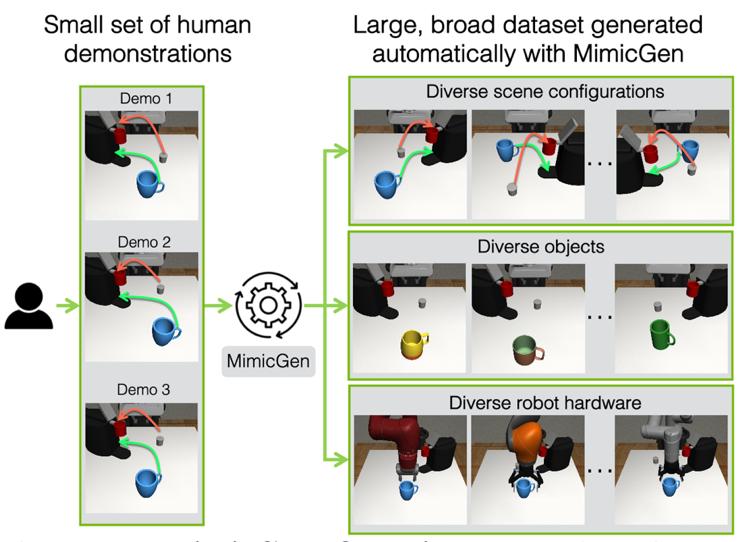
MimicGen合成数据生成示意图|图片来源:Mandlekar et al.(2023) "Mimicgen: A data generation system for scalable robot learning using human demonstrations."
MimicGen的工作流程中,系统首先对源数据集中的演示进行精细化解析,将每个演示分解为多个以对象为中心的子任务单元(图2左)。在生成新数据时,系统会选择合适的参考段,并将其智能地转换到新场景中,通过调整对象位姿来适应不同环境。最终,系统使用末端执行器控制器来实现这些转换后的目标位姿序列(图2右),确保生成数据的实用性和可靠性。
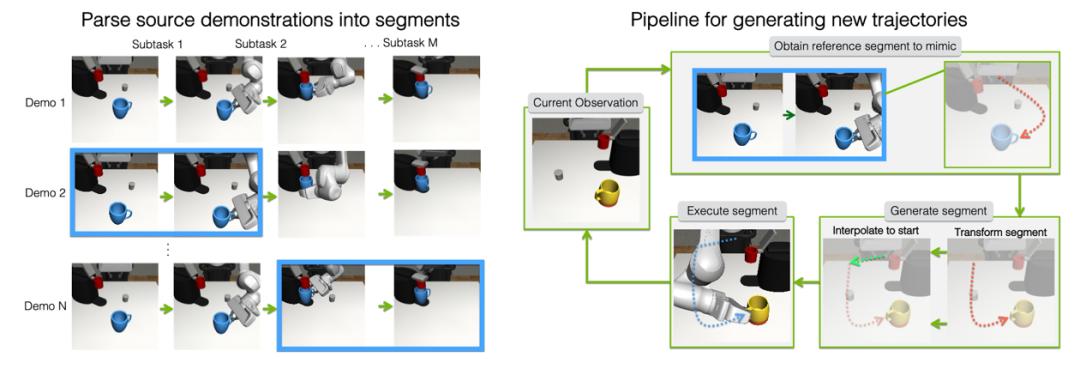
MimicGen 系统流程|图片来源:Mandlekar et al.(2023) "Mimicgen: A data generation system for scalable robot learning using human demonstrations."
在实际应用中,这些技术可以进行跨模态整合,将文本领域的控制机制与视觉生成相结合,通过属性控制提示定义视觉目标,再利用词汇化技术扩展视觉表达,最终由视觉生成模型完成具体生成任务。这种技术迁移不仅扩展了原有技术的应用范围,也为复杂数据的生成提供了更精确的控制机制。
这种方法不仅显著提高了数据生成的效率,更重要的是保证了生成数据的质量和多样性。通过这种方式,MimicGen为解决人工智能领域中的数据瓶颈问题提供了一个可行的解决方案,同时也为未来合成数据生成技术的发展指明了方向。
科学数据表示:从图神经网络到多模态数据表征
推荐理由:科学数据表示是一个致力于开发和优化用于表示、处理和分析科学数据的方法和技术的研究领域。这一领域的核心目标是找到有效方式来捕捉和表达复杂科学数据中的本质特征和关系,使这些数据能够被机器学习模型更好地理解和利用。
科学数据表示早期的研究主要集中在传统的数据结构和统计方法上,随着深度学习和大语言模型兴起,这个领域开始向更复杂和强大的表示方法发展。图神经网络、图卷积网络等开创性地将深度学习与图结构数据处理结合,变分自编码器在生物学和物理学领域展现出强大的建模能力,自然语言处理技术的进步也为科学文献的表示和理解带来了新的可能性。特别是2023年提出的图文本联合表示方法,成功地将文本语义和引用关系结构统一起来,为科学知识的表示开辟了新途径。
此外,科学数据表示领域面临的主要挑战包括如何处理多模态科学数据、如何确保表示的可解释性,以及如何在保持数据完整性的同时实现高效的压缩表示等。在这方面,南洋理工大学、北京邮电大学和字节跳动合作训练的 LLaVA-Video模型[5],通过生成跨模态的合成数据,帮助模型学习不同模态间的关联关系,大幅提升了多模态表征能力。
LLaVA-Video研究团队开发了一个创新的视频理解系统,其核心是基于大规模跨模态合成数据集LLaVA-Video-178K[5]。这个数据集包含了178K个视频样本和1.3M个指令跟随样本,涵盖了视频描述、开放式问答和多项选择问答等多种任务形式。
研究团队采用了一种基于GPT-4的三层级递归生成架构来构建视频内容的层级表示(如图 3 所示)。这种架构通过时序嵌入(Temporal Embedding)和跨模态注意力机制(Cross-modal Attention)来实现视觉和文本信息的有效整合。具体来说,对当前层级的时间点 t,以及最后的时间点 T。系统的三个层级分别承担不同的表示任务:
(a) 在第一级,为时间点 t 生成字幕时,参考了当前时间点的帧画面、前一个时间点的字幕,以及(如果适用)最近的第二级总结描述。(b) 在第二级,为时间点 t 生成字幕时,基于前一个第二区间的字幕和最近三个第一区间的字幕。(c) 在第三级,为最终时间点 T 生成整体字幕时,参考了最近的第二区间字幕和当前的第一区间字幕,生成对整个视频内容的全局语义表示。
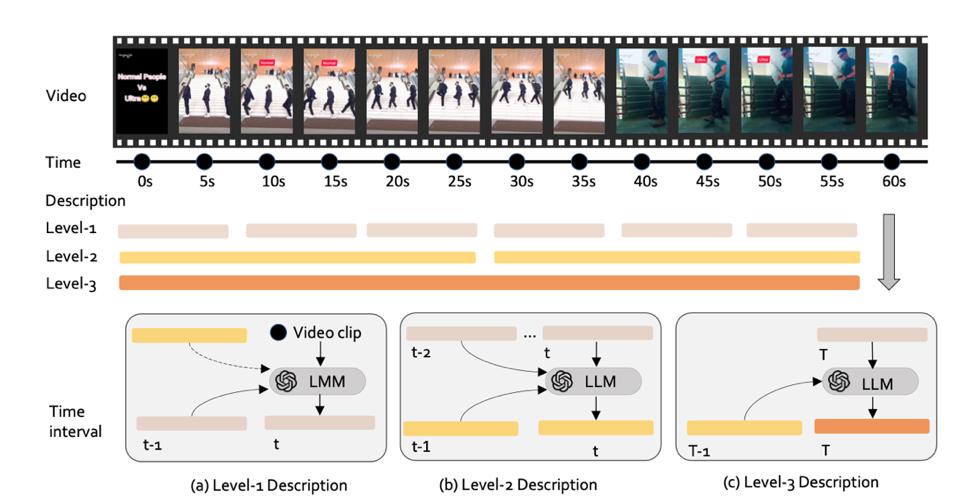
LLaVA-Video-178K视频详细描述生成流程|图片来源:Zhang et al. (2024) "Video Instruction Tuning With Synthetic Data."
这种多层级表示方法的创新之处在于它不仅解决了视频内容的时序依赖问题,还实现了视觉和语言模态的深度融合。通过递进式的多层级表示来捕捉视频内容的不同粒度特征,从而实现从局部细节到全局语义的完整表示框架。这种方法不仅提高了模型的性能,也为未来的多模态内容理解研究提供了新的思路。
随着新技术的不断涌现和交叉学科的深入融合,科学数据表示领域有望在推动科学发现和促进学科发展方面发挥更加重要的作用。
模型自我改进:通过合成数据提升AI系统性能
推荐理由:在人工智能研究领域中,模型自我改进代表了一个极具前景的发展方向。这种方法让AI系统能够通过生成和利用合成数据来增强自身能力,无需过度依赖外部数据源或更强大的教师模型。这一技术不仅降低了对高质量训练数据的依赖,更开创了AI系统自主学习和进化的新范式。随着大语言模型的发展,这种自我改进机制展现出越来越重要的价值。
模型自我改进的研究聚焦于通过合成数据增强模型性能。这个领域的一个代表性工作是自训练(Self-training)方法,模型首先在有限的标注数据上训练,然后生成新的训练样本来改进自身。另一个创新性的研究是模型蒸馏(Model Distillation)与合成数据的结合,通过生成特定的训练样本来优化知识迁移过程。这些方法展示了如何通过合成数据来实现模型能力的持续提升。
在这一领域的最新突破中,卡内基梅隆大学和清华大学研究团队开发的SELF-GUIDE方法[6]展示了显著成果。这种创新方法通过设计高效的多阶段生成机制,使语言模型能够自主生成任务特定的训练数据。系统通过逐步生成“输入-输出”数据对,并经过严格的筛选过程,确保生成数据的质量和相关性。这些自生成的数据随后被用于模型的进一步微调,形成一个良性的自我提升循环。
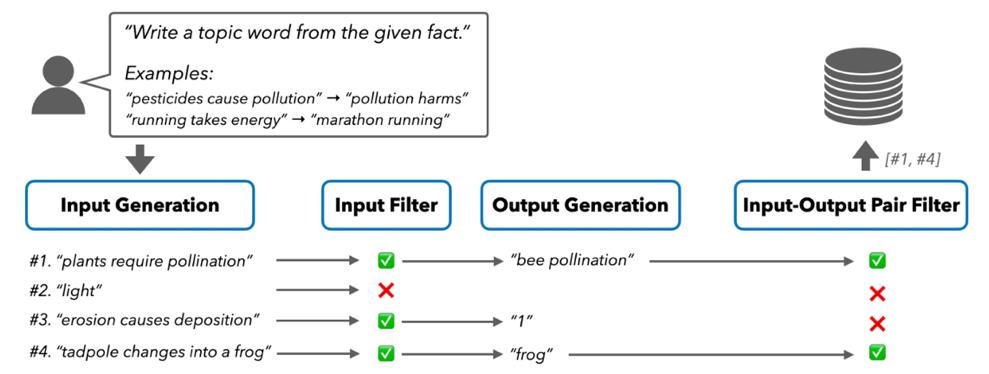
SELF-GUIDE 针对生成任务的流程|图片来源:Zhao et al. (2024) "Self-guide: Better task-specific instruction following via self-synthetic finetuning."
研究结果令人振奋:SELF-GUIDE在多个任务上都取得了显著的性能提升。在分类任务中,模型性能获得了约15%的绝对提升;在生成任务中,提升幅度更是达到了约18%。这些数据充分证明了该方法在提升模型能力方面的有效性。
SELF-GUIDE的成功不仅证明了模型自我改进策略的可行性,也为未来AI系统的发展提供了新的思路。这种自主学习和改进的能力,可能会带来更智能、适应性更强的AI系统,推动整个领域向着更高水平发展。通过持续的自我改进,AI系统有望在更多复杂任务中展现出更强的性能和适应能力
数据基础设施:人体蛋白质组计划
推荐理由: 首次提出构建人体蛋白质组的精确“导航系统”[18],不仅将彻底改变我们对人体生命活动的认识,随着单细胞蛋白质组学等技术[19]的快速发展,更有望推动医学范式从被动治疗向主动预防和精确医疗转变。
在生命科学研究中,基因组告诉我们生命的可能性,蛋白质组则展示了生命的现实状态。人体内约37万亿个细胞虽然共享相同的基因组,却能展现出丰富多样的形态和功能。这种神奇的分化和调控过程,正是由蛋白质的精确表达和调控网络所主导。然而,目前我们对人体蛋白质组的认识仍然十分有限,这极大地制约了精准医疗的发展。
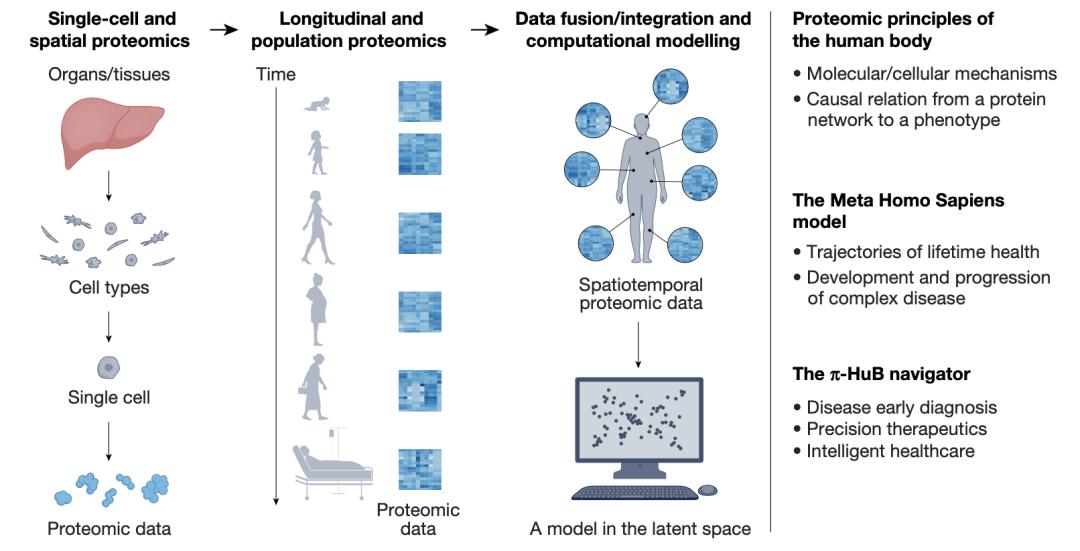
π-HuB项目的总体目标|图片来源:He, F., Aebersold, R., Baker, M.S. et al. π-HuB: the proteomic navigator of the human body. Nature 636, 322–331 (2024)."
π-HuB项目提出了三个突破性的研究目标:首先是揭示人体的构建原理,通过最新的单细胞蛋白质组学技术,绘制不同类型细胞中蛋白质的精确组成及其调控网络;其次是建立“元人类” (Meta Homo Sapiens) 计算模型,追踪记录人体蛋白质组在不同生命阶段的动态变化规律;最后是开发π-HuB导航系统,将蛋白质组学数据转化为疾病预防、诊断和治疗的精确指导。
在技术路线上,该项目采用了多层次、多维度的研究策略。在细胞水平,运用最新的单细胞蛋白质组学技术,实现对人体主要器官细胞类型的精确分析;在群体水平,通过大规模队列研究[20],揭示生活方式、环境因素等对蛋白质组的影响;在临床应用层面,通过建立标准化的生物样本库和数据分析平台,推动蛋白质组学在精准医疗中的转化应用。
研究成果的应用前景令人振奋。在第一阶段(2024-2033年),项目将重点实现三个突破:完成人体主要器官的细胞类型蛋白质图谱;建立基于蛋白质组学的健康评估体系;开发新的疾病早期诊断标志物和治疗靶点。这些成果将为实现更具有实践智慧的精准医学奠定坚实基础,推动医学模式从被动治疗向主动预防转变。
π-HuB项目的创新性不仅体现在其科学目标上,也体现在其组织模式上。项目采用开放科学的理念,建立了国际化的研究团队网络,并承诺将研究数据和分析工具向全球科研界开放共享。这种协作模式将大大加速蛋白质组学研究的进展。π-HuB项目的启动,标志着人类探索生命奥秘和追求健康的征程又迈出了重要一步。
挑战与展望
虽然 OpenAI的CEO Sam Altman 预见AI最终将能产生足够优质的合成数据来训练自身,但有研究表明[21],劣质信息和不当的训练方法仍可能导致LLMs“模型崩溃”。因此合成数据虽然潜力巨大,但在实际应用中仍面临着诸多挑战。
数据质量与保真度问题至关重要。合成数据的质量直接影响模型性能。基于虚假、幻觉或有偏差的数据训练的模型不仅可能在现实场景中表现不佳,缺乏泛化能力[22],如果设计和验证不当,还可能会放大已有偏差或引入新的偏差[23]。去污染评估(decontamination evaluation)难度问题仍需进一步探索。由于合成数据可能包含重述的基准数据版本,传统的词级别去污染方法可能会失效[24],导致无法有效区分模型是真正理解和学习了新知识,还是仅仅在记忆和重复训练数据中的内容。隐私与伦理问题也依然严峻。尽管合成数据提供了一些不损害个人隐私的途径[25],但在敏感领域中使用合成数据时仍存在伦理问题。有研究[26]表明可以从训练数据集中提取特定信息,这意味着合成数据可能会在无意中暴露基础训练数据的某些敏感信息和隐私内容[27]。
当然,在面对挑战的同时,合成数据未来同样有下面几个具有前景的研究发展方向值得期待。
数据质量与多样性提升。合成数据未来研究应专注于开发基于GANs和扩散模型等的新技术,并结合领域特定知识,通过RAG等方法确保数据质量和多样性,拓展到包括医疗、金融和社会科学等应用领域。
数据质量监管机制研究。随着AI复杂性提升,传统数据评估方法已不足以应对挑战。需要建立更系统化的监管框架,实现合成数据的全面质量评估、自动化筛查和多场景验证。
探索合成数据的规模效应。鉴于一些经过精心训练的小型语言模型,能超出Chinchilla定律(模型性能与训练数据规模和模型参数量呈正比)的预测,未来研究需要探索合成数据规模的“质量-数量”权衡机制,以找到提升模型性能的最优数据策略。
自我改进能力的涌现研究。最新研究显示出积极进展,但仍需深入探索其理论基础、局限性和潜在风险,从而推动更具适应性和自主性的AI学习过程。
多源数据融合基础设施建设。需要解决数据标准化和语义对齐问题,特别是在处理跨组织、跨领域的敏感数据时,如何在促进数据共享的同时确保数据安全与隐私问题。近期,Anthropic 开源的「模型上下文协议」MCP(Model Context Protocol)[28] 已经迈出了重要一步。
总之,虽然目前仍面临诸多挑战,但正如许多研究者所预见的,合成数据不仅是解决当前AI发展瓶颈的工具,更可能成为开启下一代人工智能革命的钥匙。特别是在自我改进能力方面的研究,能帮助我们实现从狭义AI到通用人工智能的跨越,推动人类和AI向更智能、更加美好的未来迈进。
参考文献
[1] Villalobos,Pablo,et al. "Will we run out of data? an analysis of the limits of scaling datasets in machine learning." arXiv preprint arXiv:2211.04325 (2022)
推荐理由:深入分析机器学习数据集扩展的极限问题,对当前大模型发展中的数据瓶颈提供了重要见解。
[2] Gilardi,Fabrizio,Meysam Alizadeh,and Maël Kubli. "ChatGPT outperforms crowd workers for text-annotation tasks." Proceedings of the National Academy of Sciences 120.30 (2023): e2305016120.
推荐理由:首次系统性地证明ChatGPT在文本标注任务上优于人工众包,为AI辅助数据标注提供了实证研究支持。
[3] Abay,Nazmiye Ceren,et al. "Privacy preserving synthetic data release using deep learning." Machine Learning and Knowledge Discovery in Databases: European Conference,ECML PKDD 2018,Dublin,Ireland,September 10–14,2018,Proceedings,Part I 18. Springer International Publishing,2019.
推荐理由:提出了基于深度学习的隐私保护合成数据生成方法,在数据隐私和效用之间取得了良好平衡。
[4] Mandlekar,Ajay,et al. "Mimicgen: A data generation system for scalable robot learning using human demonstrations." arXiv preprint arXiv:2310.17596 (2023).
推荐理由:创新性地提出了基于人类示范的机器人学习数据生成系统,为解决机器人学习中的数据瓶颈提供了新思路。
[5] Zhang,Yuanhan,et al. "Video Instruction Tuning With Synthetic Data." arXiv preprint arXiv:2410.02713 (2024).
推荐理由:探索了视频指令微调的合成数据生成方法,为多模态大模型的训练提供了新的视角。
[6] Zhao,Chenyang,et al. "Self-guide: Better task-specific instruction following via self-synthetic finetuning." arXiv preprint arXiv:2407.12874 (2024).
推荐理由:提出了自生成式指令微调方法,显著提升了模型对特定任务的理解能力。
[7] Chen,Zixiang,et al. "Self-play fine-tuning converts weak language models to strong language models." arXiv preprint arXiv:2401.01335 (2024).
推荐理由:创新性地提出了自对弈式微调方法,证明了弱模型可以通过自我提升变强。
[8] Wu,Tianhao,et al. "Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge." arXiv preprint arXiv:2407.19594 (2024).
推荐理由:提出了创新的元奖励机制来改进语言模型对齐,为模型自我提升提供了新框架。
[9] Liang,Yiming,et al. "I-SHEEP: Self-Alignment of LLM from Scratch through an Iterative Self-Enhancement Paradigm." arXiv preprint arXiv:2408.08072 (2024).
推荐理由:提出了从零开始的LLM自对齐迭代增强范式,为模型对齐提供了全新思路。
[10] Van Breugel,Boris,Zhaozhi Qian,and Mihaela Van Der Schaar. "Synthetic data,real errors: how (not) to publish and use synthetic data." International Conference on Machine Learning. PMLR,2023.
推荐理由:深入分析了合成数据使用中的常见错误,提供了实用的合成数据发布和使用指南。
[11] Barbierato,Enrico,et al. "A methodology for controlling bias and fairness in synthetic data generation." Applied Sciences 12.9 (2022): 4619.
推荐理由:提出了一种在合成数据生成中控制偏差和公平性的方法,旨在提高数据的公正性,该方法在减少算法偏差和促进公平性方面具有重要意义,特别是在敏感应用领域。
[12] Mattern,Justus,et al. "Membership inference attacks against language models via neighbourhood comparison." arXiv preprint arXiv:2305.18462 (2023).
推荐理由:这项研究提出了基于邻域比较的创新成员推理攻击方法,有效揭示了语言模型在训练数据隐私保护方面的潜在漏洞。
[13] Xu Guo&Yiqiang Chen.(2024) "Generative AI for Synthetic Data Generation: Methods,Challenges and the Future"
推荐理由:全面梳理了生成式AI在合成数据生成领域的最新进展和技术挑战,为研究者提供了完整的领域发展全貌。
[14] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,”2014
推荐理由:这是GAN领域的开山之作,开创了生成对抗网络的研究方向并奠定了理论基础。
[15] D. Chen, C. Lee, Y. Lu, D. Rosati, and Z. Yu, “Mixture of soft prompts for controllable data generation,” in Findings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds.
Singapore: Association for Computational Linguistics, Dec. 2023, pp. 14 815–14 833. [Online]. Available: https://aclanthology.org/2023.findings-emnlp.988
推荐理由:在EMNLP发表的研究创新性地提出了混合软提示方法来实现可控的数据生成,为提示工程提供了新思路。
[16] Y. Yu, Y. Zhuang, J. Zhang, Y. Meng, A. Ratner, R. Krishna, J. Shen, and C. Zhang, “Large language model as attributed training data generator: A tale of diversity and bias,” in Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
[Online]. Available: https://openreview.net/forum?id=6hZIfAY9GD
推荐理由:深入探讨了大语言模型在训练数据生成过程中的多样性和偏见问题,为提升AI系统的公平性提供了重要参考。
[17] L. Reynolds and K. McDonell, “Prompt programming for large language models: Beyond the few-shot paradigm,” 2021.
推荐理由:突破性地探索了超越少样本范式的提示编程方法,为大语言模型的提示工程开辟了新方向。
[18] He, F., Aebersold, R., Baker, M.S. et al. π-HuB: the proteomic navigator of the human body. Nature636, 322–331 (2024). https://doi.org/10.1038/s41586-024-08280-5
推荐理由:这篇Nature文章介绍了突破性的人体蛋白质组导航器 π-HuB平台,为理解人体生理机制和疾病发展提供了新视角。
[19] Kelly, R.T. Single-cell proteomics: progress and prospects. Mol. Cell. Proteomics 19, 1739–1748 (2020).
推荐理由:系统总结了单细胞蛋白质组学的技术进展和应用前景,为该领域研究者提供了重要参考。
[20] Eldjarn, G.H. et al. Large-scale plasma proteomics comparisons through genetics and disease associations. Nature 622, 348–358 (2023).
推荐理由:提 在Nature发表的大规模血浆蛋白质组学研究,通过与遗传学和疾病关联分析揭示了重要的生物学机制。
[21] Shumailov,I.,Shumaylov,Z.,Zhao,Y. et al. AI models collapse when trained on recursively generated data. Nature 631,755–759 (2024). https://doi.org/10.1038/s41586-024-07566-y
推荐理由:Nature上发表的重要研究,揭示了AI模型在递归生成数据训练时的崩溃现象,对当前生成式AI的局限性提供了关键洞察。
[22] Y. Zhu, R. Kiros, R. Zemel, R. Salakhutdinov, R. Urtasun, A. Torralba, and S. Fidler, “Aligning books and movies: Towards story-like visual explanations by watching movies and reading books,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 19–27
推荐理由:开创性地探索了电影和图书内容的跨模态对齐问题,为视觉叙事理解提供了重要的研究基础,是多模态学习领域的经典文献。
[23] C. Peng, X. Yang, A. Chen, K. E. Smith, N. PourNejatian, A. B.
Costa, C. Martin, M. G. Flores, Y. Zhang, T. Magoc et al., “A study of generative large language model for medical research and healthcare,”arXiv preprint arXiv:2305.13523, 2023.
推荐理由:系统研究了大语言模型在医疗研究和健康护理领域的应用前景,深入分析了其潜力和局限性。
[24] S. Moore, R. Tong, A. Singh, Z. Liu, X. Hu, Y. Lu, J. Liang, C. Cao, H. Khosravi, P. Denny et al., “Empowering education with llms-the next-gen interface and content generation,” in International Conference on Artificial Intelligence in Education. Springer, 2023, pp. 32–37.
推荐理由:探讨了大语言模型在教育领域的创新应用,特别关注了接口设计和内容生成方面的突破。
[25] N. Rane, “Role and challenges of chatgpt and similar generative artificial intelligence in business management,” Available at SSRN 4603227, 2023.
推荐理由:Rane (2023) 详细分析了ChatGPT等生成式AI在商业管理中的角色定位和面临的挑战,为企业应用提供了实用的参考框架。
[26] Y. Cao, S. Li, Y. Liu, Z. Yan, Y. Dai, P. S. Yu, and L. Sun, “A comprehensive survey of ai-generated content (aigc): A history of generative ai from gan to chatgpt,” arXiv preprint arXiv:2303.04226, 2023.
推荐理由:全面回顾了AI生成内容(AIGC)的发展历程,从GAN到ChatGPT的技术演进,是理解生成式AI发展的重要综述。
[27] A. Bauer, S. Trapp, M. Stenger, R. Leppich, S. Kounev, M. Leznik, K. Chard, and I. Foster, “Comprehensive exploration of synthetic data generation: A survey,” arXiv preprint arXiv:2401.02524, 2024
推荐理由:全面综述了合成数据生成的各种方法和应用,为研究者提供了系统性的参考框架。
[28] https://www.anthropic.com/news/model-context-protocol
推荐理由:通过MCP协议为大语言模型在长文本处理能力上的突破性进展,为大模型架构优化提供了新思路。
出品:漆远、吴力波、张江
运营:孟晋宇、王婷
撰稿:张江、杨燕青、王婷、王朝会、十三维、周莉、梁金、袁冰、江千月、刘志毅
鸣谢(按姓氏拼音顺序,排名不分先后):
曹风雷 、陈小杨 、程远、杜沅岂 、段郁、方榯楷 、付彦伟、 高悦、黄柯鑫、李昊、刘圣超、谭伟敏、吴泰霖、吴艳玲、向红军、张骥、张艳、朱思语
AI+Science 读书会
详情请见:
推荐阅读
1. 2. 《AI×SCIENCE十大前沿观察》1:基于LLM的科学研究
3. 《AI×SCIENCE十大前沿观察》2:垂直领域科学大模型
4. 《AI×SCIENCE十大前沿观察》3:融入先验知识的AI模型
5. 《AI×SCIENCE十大前沿观察》4:AI科学家
6. 《AI×SCIENCE十大前沿观察》5:复杂世界的多智能体建模
7. 《AI×SCIENCE十大前沿观察》6:AI 仿真与系统模拟
8. 《AI×SCIENCE十大前沿观察》7:物理世界的第一性原理
9. 《AI×SCIENCE十大前沿观察》8:科学启发的AI新架构
原标题:《《AI×SCIENCE十大前沿观察》9:合成数据和数据基础设施》
阅读原文